Co je sloupcový strom?
Uzel Stůl ve dřevě převádí zdrojová data prezentovaná ve formě ploché (dvourozměrné) tabulky do hierarchické (stromové) podoby. Počet úrovní vnoření není omezen.
Порты
vchod
- Zdroj vstupních dat — port pro připojení sady vstupních dat ve formě tabulky.
Výkon
- Zdroj výstupních dat — port, který odesílá data poté, co byla převedena do stromové podoby.
Průvodce instalací
V okně nastavení musíte nakonfigurovat shodu mezi vstupními daty, která se nachází vlevo v poli Zdrojová sada sloupců, a vytvořený datový strom, který se nachází vpravo v polích uzel stromu и Související obory.
V počáteční fázi je v pravém poli k dispozici pouze jeden kořenový adresář – Kořen.
Chcete-li vytvořit hierarchickou strukturu, musíte do kořenové složky přidat alespoň jeden podřízený uzel. To lze provést dvěma způsoby:
- Vyberte kořenový uzel a pomocí tlačítka přidejte podřízený uzel.
- Příkaz kontextové nabídky Přidejte podřízený uzel.
Poté bude vytvořen podřízený uzel, pro který můžete definovat hodnotu následujících polí:
- název — jedinečný název sloupce v rámci jedné datové sady. Může se skládat z:
- velká nebo malá písmena latinky;
- podtržítka;
- čísla (nesmí být prvním znakem).
Pro podřízené uzly je možné vytvořit uzly stejné hierarchické úrovně. To lze provést z kontextové nabídky podřízeného uzlu výběrem Přidejte sousední uzel, nebo po výběru požadovaného uzlu klikněte na tlačítko pro vytvoření sousedního uzlu.
Po vytvoření lze hodnoty zadaných polí pro podřízený uzel změnit. K tomu můžete použít klávesovou zkratku F2po předchozím výběru požadovaného uzlu. To lze také provést pomocí příkazu kontextové nabídky Editace. , nebo po zvýraznění požadovaného uzlu stiskněte tlačítko .
knoflík Načíst z XSD. můžete vybrat soubor *.xsd, ze kterého bude načtena struktura výstupního uzlu (tlačítko je také duplikováno příkazem kontextové nabídky). Dialogové okno, které se objeví, bude obsahovat následující pole:
- XSD soubor — pole pro výběr souboru *.xsd (nelze upravovat).
- Jmenný prostor — výběr jmenného prostoru ze seznamu všech jmenných prostorů popsaných v souboru xsd omezí výběr kořenového prvku pouze na určený prostor. Výchozí hodnota je Všechny jmenné prostory.
- Kořenový prvek — výběr kořenového uzlu ze seznamu ve staženém souboru *.xsd. Ve výchozím nastavení je nastavena hodnota prvního kořenového uzlu vybraného souboru.
- Hloubka rekurze — maximální počet rekurzí při rozšiřování rekurzivních uzlů. Volitelné od 0 do 3. Výchozí hodnota je 1, což znamená: každý rekurzivní uzel bude automaticky rozbalen, ale rekurzivní uzly v rámci těchto uzlů zůstanou nerozbalené. Rozšíření rekurzivních uzlů lze navíc provést ručně po vytvoření stromu. Pokud je nastaveno na 0, všechny rekurzivní uzly nebudou automaticky rozbaleny.
- Generujte popisky uzlů pomocí xsd:documentation — pokud je tento parametr povolen, pak uzly stromu obdrží hodnoty z prvního neprázdného řádku souboru *.xsd jako štítky. Pokud dokumentace chybí nebo je tato možnost zakázána, je označení uzlu vygenerováno z názvu prvku nebo atributu.
Po vyplnění všech polí musíte kliknout na tlačítko Stažení a schéma XSD bude načteno pro další práci.
Kliknutím pravého tlačítka myši v oblasti tvorby struktury Výstupní strom vyvolá se kontextové menu, ve kterém můžete volbu dodatečně povolit/zakázat Při publikování vyloučit kořenový uzel. Když je nastaven příznak, je kořenový uzel vyloučen ze zpráv REST a SOAP Datový strom (ve výchozím nastavení je tato možnost zakázána). Při publikování podmodelu s výstupním portem typu Datový strom tato vlastnost musí být nakonfigurována v Průvodci konfigurací vstupního portu výstupního uzlu Podmodely (Viz obrázek 1).
Tlačítko Generovat podřízené prvky rozšiřuje rekurzivní uzel (přidává všechny poduzly rekurzivního uzlu do stromu dat). Rekurzivní uzel, který již byl rozšířen, nelze znovu rozšířit. Pokud není načteno XSD schéma (nebyla provedena akce „Načíst z XSD“) nebo načtený strom neobsahuje rekurzivní uzly, pak je tlačítko skryté/neaktivní.
Tlačítko Další rekurzivní neexpandovaný uzel vybere další rekurzivní neexpandovaný uzel po aktuálně vybraném uzlu jako aktuální uzel. Chcete-li vybrat první rekurzivní uzel, musíte vybrat kořenový uzel a přesunout se na další rekurzivní neexpandovaný uzel. Pokud není načteno XSD schéma (nebyla provedena akce „Načíst z XSD“) nebo načtený strom neobsahuje rekurzivní uzly, pak je tlačítko skryté/neaktivní.
Jakmile je vytvořena veškerá potřebná hierarchie, můžete použít tlačítko Propojte vše automaticky, který automaticky propojí vstupní a výstupní pole, pokud mají stejný název a datový typ. Každý podřízený uzel lze také přiřadit ke zdroji dat pomocí příkazu kontextové nabídky Propojit automaticky. V tomto případě bude uzel přidružen k jednomu ze vstupních uzlů se stejným názvem a datovým typem.
Kromě automatického propojování lze pomocí této metody ručně propojit vstupní a výstupní uzly Drag-and-droppřetažením štítků polí z levého seznamu polí na položku z pravého seznamu polí. V tomto případě nejsou hodnoty názvu pole důležité, ale datové typy se musí stále shodovat.
Vytvořená spojení mezi uzly lze odstranit. Všechna spojení lze smazat najednou pomocí tlačítka Odstraňte všechna připojenínebo pomocí příkazu kontextové nabídky Odstraňte všechna připojenízavolal na některý z prvků v seznamu. Chcete-li odstranit konkrétní připojení, můžete použít příkaz kontextové nabídky Smazat připojenízavolal jeden ze souvisejících prvků. Druhou možností je přímo kliknout levým tlačítkem myši na připojení, které je třeba odstranit, a kliknout na tlačítko smazat připojení (když na něj najedete myší).
Vytvořené podřízené uzly lze uspořádat ve vhodném pořadí. Chcete-li to provést, musíte vybrat uzel, který je třeba přesunout, a kliknout na tlačítka Posunout nahoru (kombinace klávesových zkratek Ctrl+Up) Nebo Posuňte se dolů (kombinace klávesových zkratek Ctrl+Dolů). Podobné příkazy jsou v kontextové nabídce každého uzlu v pravém okně (kořenový uzel Kořen nelze přesunout).
- filtrování – umožňuje vybrat pole podle názvu nebo jeho části.
- Vyhledávání – umožňuje označit pole jménem nebo jeho částí.
Chcete-li resetovat parametry filtrování nebo vyhledávání, musíte použít tlačítko
Podřízený uzel můžete odstranit kliknutím na ikonu Odstranit (klávesová zkratka Vymazat), který se nachází na pravé straně řádku podřízeného uzlu a je viditelný, když najedete na řádek. Všechny vytvořené podřízené uzly lze smazat kliknutím na tlačítko Smazat vše. (kombinace klávesových zkratek Shift + Delete).
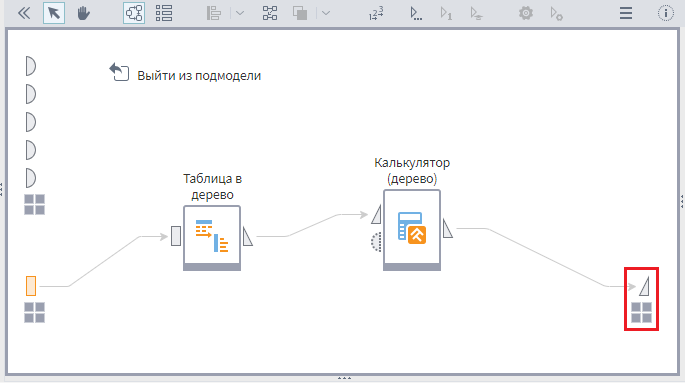
Hierarchická struktura prvků nazývaných uzly (vrcholy). Na nejvyšší úrovni je pouze jeden uzel – kořen stromu. Každý uzel kromě kořene je připojen pouze k jednomu uzlu na vyšší úrovni. Každý prvek může být připojen hranou k jednomu nebo více prvkům na další nižší úrovni. Prvky, které nemají potomky, se nazývají listy. Od kořene k libovolnému vrcholu vede jedna cesta. Jakýkoli uzel ve stromu s dětmi na všech úrovních také tvoří strom nazývaný podstrom.
Podmínky:
- Kořenový uzel – nejvyšší uzel stromu.
- kořen – jeden z vrcholů, na žádost pozorovatele.
- List, list nebo koncový uzel – uzel, který nemá žádné potomky.
- Vnitřní uzel – jakýkoli uzel stromu, který má potomky, a není tedy listovým uzlem.
- Strom je zvažován orientované, pokud žádná hrana nejde do kořene.
- Plně propojený klíč — identifikátor záznamu, který je tvořen zřetězením všech klíčů instancí nadřazených záznamů (skupin).
- M-ary strom — počet podstromů daného uzlu tvoří stupeň uzlu, maximální hodnota m stupně všech uzlů ve stromu je stupeň stromu. Strom stupně 2 se nazývá binární strom. Pokud je určeno pořadí vrcholů ve stromu na každé úrovni, pak se takový strom nazývá uspořádaný
Binární vyhledávací strom
Hledat – O(log n); Vložení – O(log n); Odstranění je O(log n);
Jedná se o binární strom, pro který jsou splněny následující podmínky:
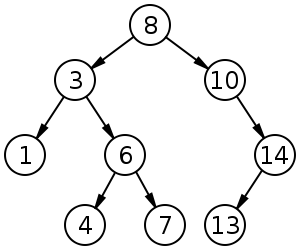
- Každý uzel nemá více než dva potomky (protože je binární).
- Všechny uzly levého podstromu libovolného uzlu X mají hodnoty datového klíče menší než hodnota datového klíče samotného uzlu X.
- Všechny uzly v pravém podstromu libovolného uzlu X mají hodnoty datového klíče větší nebo rovné hodnotě datového klíče samotného uzlu X.
AVL-strom
Výška vyvážená binární vyhledávací strom: pro každý vrchol se výška jeho dvou podstromů neliší o více než 1.
Červeno-ebenový strom
Červeno-černé stromy jsou jedním ze způsobů, jak stromy vyvážit. Název pochází ze standardního zbarvení uzlů takových stromů v červené a černé. Barvy uzlů se používají při vyvažování stromu. Během operací vkládání a mazání může být nutné podstromy otočit, aby bylo dosaženo rovnováhy stromu. Odhad pro průměrnou dobu i pro nejhorší případ je O(log n).
Červeno-černý strom je binární vyhledávací strom, ve kterém má každý uzel atribut barvy, který nabývá hodnot červená nebo černá.
Jako binární strom má červeno-černá vlastnosti:
Kromě běžných požadavků na binární vyhledávací stromy se na červeno-černé stromy vztahují následující požadavky:
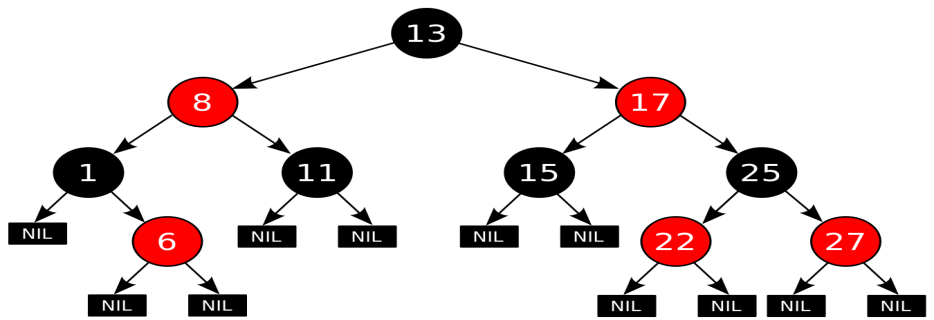
- Uzel je buď červený nebo černý.
- Kořen je černý. (V jiných definicích je toto pravidlo někdy vynecháno. Toto pravidlo má malý vliv na analýzu, protože kořen lze vždy změnit z červené na černou, ale ne nutně naopak).
- Všechny listy (NIL) jsou černé.
- Oba potomci každého červeného uzlu jsou černé.
- Každá jednoduchá cesta z daného uzlu k libovolnému listovému uzlu, který je jeho potomkem, obsahuje stejný počet černých uzlů.
Počet černých uzlů na větvi od kořene po list se nazývá černá výška stromu. Uvedené vlastnosti zaručují, že nejdelší větev od kořene po list není více než dvakrát delší než jakákoliv jiná větev od kořene po list. Abyste pochopili, proč tomu tak je, zvažte strom s černou výškou 2. Nejkratší možná vzdálenost od kořene k listu je dvě – když jsou oba uzly černé. Nejdelší vzdálenost od kořene k listu je čtyři – uzliny jsou zbarveny (od kořene k listu) takto: červená, černá, červená, černá. Černé uzly sem nelze přidat, protože by to porušilo vlastnost 4, ze které vyplývá správnost konceptu výšky černé. Vzhledem k tomu, že podle vlastnosti 3 mají červené uzly jistě černé následníky, dva červené uzly v řadě nejsou v takovém pořadí povoleny. Nejdelší cesta, kterou můžeme sestrojit, se tedy skládá ze střídání červených a černých uzlů, což nás vede k dvojnásobné délce cesty procházející pouze černými uzly. Všechny operace na stromě musí umět pracovat s uvedenými vlastnostmi. Zejména tyto vlastnosti musí být zachovány při vkládání a mazání.
Hromada
Specializovaný strom, který splňuje vlastnost *heap: *if B je podřízeným uzlem uzlu A, pak klíč(A) ≥ klíč(B). To znamená, že prvek s největším klíčem je vždy kořenový uzel haldy, takže takové haldy se někdy nazývají max-hromady (alternativně, pokud je srovnání obrácené, pak nejmenším prvkem bude vždy kořenový uzel, takové haldy se nazývají min-hromady). Neexistuje žádné omezení počtu podřízených uzlů, které má každý uzel haldy, i když v praxi obvykle nejsou více než dva. Halda je nejúčinnější implementací prioritní fronty. Haldy jsou kritické v některých účinných grafových algoritmech, jako je Dijkstrův d-heap algoritmus a heapsort.
Binární halda, pyramida nebo třídící strom je binární strom, pro který jsou splněny tři podmínky:
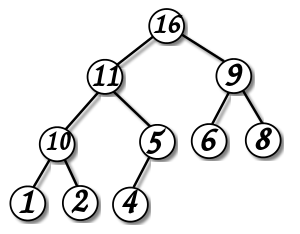
- Hodnota v žádném vrcholu není menší než hodnoty jeho potomků.
- Hloubka všech listů (vzdálenost ke kořeni) se neliší o více než 1 vrstvu.
- Poslední vrstva je vyplněna zleva doprava bez „děr“.
B-strom
B-strom je struktura úložiště dat, která je typem vyhledávacího stromu. Vlastnosti B-stromů jsou:
- váhy,
- větvení,
- třídění
- logaritmický O (log n) provozní doba všech standardních operací (vyhledávání, vkládání, mazání).
Rovnováha znamená, že všechny listy jsou ve stejné vzdálenosti od kořene. Na rozdíl od binárních stromů umožňují B-stromy velké množství dětí pro každý jeden uzel. Tato vlastnost se nazývá větvení. B-stromy jsou díky své větvené povaze velmi vhodné pro ukládání velkých sekvenčních bloků dat, takže tato struktura se často používá v databázích a souborových systémech.
Z hlediska fyzické organizace je B-strom reprezentován jako víceseznamová struktura paměťových stránek, to znamená, že každý uzel stromu odpovídá paměťovému bloku (stránce). Vnitřní a listové stránky mají obvykle různé struktury.
Pořadí(m) B-stromu je maximální počet potomků pro jakýkoli uzel. Kromě uzlů je ve stromu ještě jedna entita – klíče. Obsahují všechny užitečné informace. Každý uzel stromu může být reprezentován jako uspořádaná sekvence ”dítě1; klíč1; dítě2; klíč2; . dítě(N-1); klíč(N-1); potomekN”. Je důležité poznamenat, že klíče jsou umístěny mezi odkazy na děti, a proto je vždy o 1 klíčů méně. Existuje několik klíčových pravidel při organizování B-stromu:
- Každý uzel obsahuje přísně méně než m (stromové pořadí) potomků.
- Každý uzel obsahuje ne méně než m/2 potomci.
- Kořen může obsahovat méně než m/2 potomci.
- Kořenový uzel má alespoň 2 potomky, pokud se nejedná o list.
- Všechny listy jsou na stejné úrovni a obsahují pouze data (klíče). Ale tohle neznamená to že klíče jsou jen v listech.
Klíče ve vnitřním uzlu jsou obklopeny ukazateli záznamu nebo posuny ukazujícími na klíče, které jsou buď stále větší, nebo postupně menší než obklopený klíč. Například všechny klíče menší než 22 jsou adresovány levým odkazem, všechny větší odkazem pravým. Pro jednoduchost zde nejsou zobrazeny adresy záznamů spojené s každým klíčem.
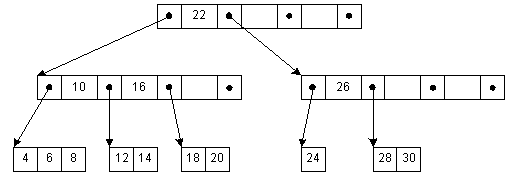
strom B+
strom B+ je datová struktura založená na B-stromu, vyvážený n-ární vyhledávací strom s proměnným, ale často velkým počtem dětí na uzel. Strom B+ se skládá z kořene, vnitřních uzlů a listů; kořenem může být list nebo uzel se dvěma nebo více dětmi.
Struktura byla původně zamýšlena k ukládání dat pro efektivní vyhledávání v blokově orientovaném úložném prostředí – zejména pro souborové systémy; aplikace je způsobena tím, že na rozdíl od binárních vyhledávacích stromů, B+ stromy mají velmi vysoký poměr větvení (počet ukazatelů z nadřazeného uzlu na jeho potomky, obvykle řádově 100 nebo více), což snižuje počet I/O operací, které vyžadují hledání prvku ve stromu.
Konstrukce B+-stromu může vyžadovat restrukturalizaci mezistruktury, je to způsobeno tím, že počet klíčů v každém uzlu (kromě kořene) musí být od t na 2tKde t — stupeň (nebo pořadí) stromu. Při pokusu o vložení do uzlu 2t+1Klíč th je nezbytný pro rozdělení tohoto uzlu t + 1-tý klíč, který je umístěn na sousední vrstvě stromu. Zvláštním případem je rozdělení kořene, protože v tomto případě se zvyšuje počet vrstev stromu. Zvláštností dělení listu B+-stromu je, že je rozdělen na nestejné části. Když je interní uzel nebo kořen rozdělen, vytvoří se uzly se stejným počtem klíčů k. Rozštěpení listu může způsobit „řetězovou reakci“ dělení uzlu končícího u kořene.
Vlastnosti struktury:
- Nezávislost programu na struktuře informačního záznamu je snadno realizovatelná.
- Hledání nutně končí v listu.
- Smazání klíče má tu výhodu, že k vymazání dojde vždy z listu.
- Ostatní operace se provádějí podobně jako u B-stromů.
- B+ stromy vyžadují k reprezentaci více paměti než klasické B-stromy.
- B+ stromy mají možnost přistupovat ke klíčům postupně.
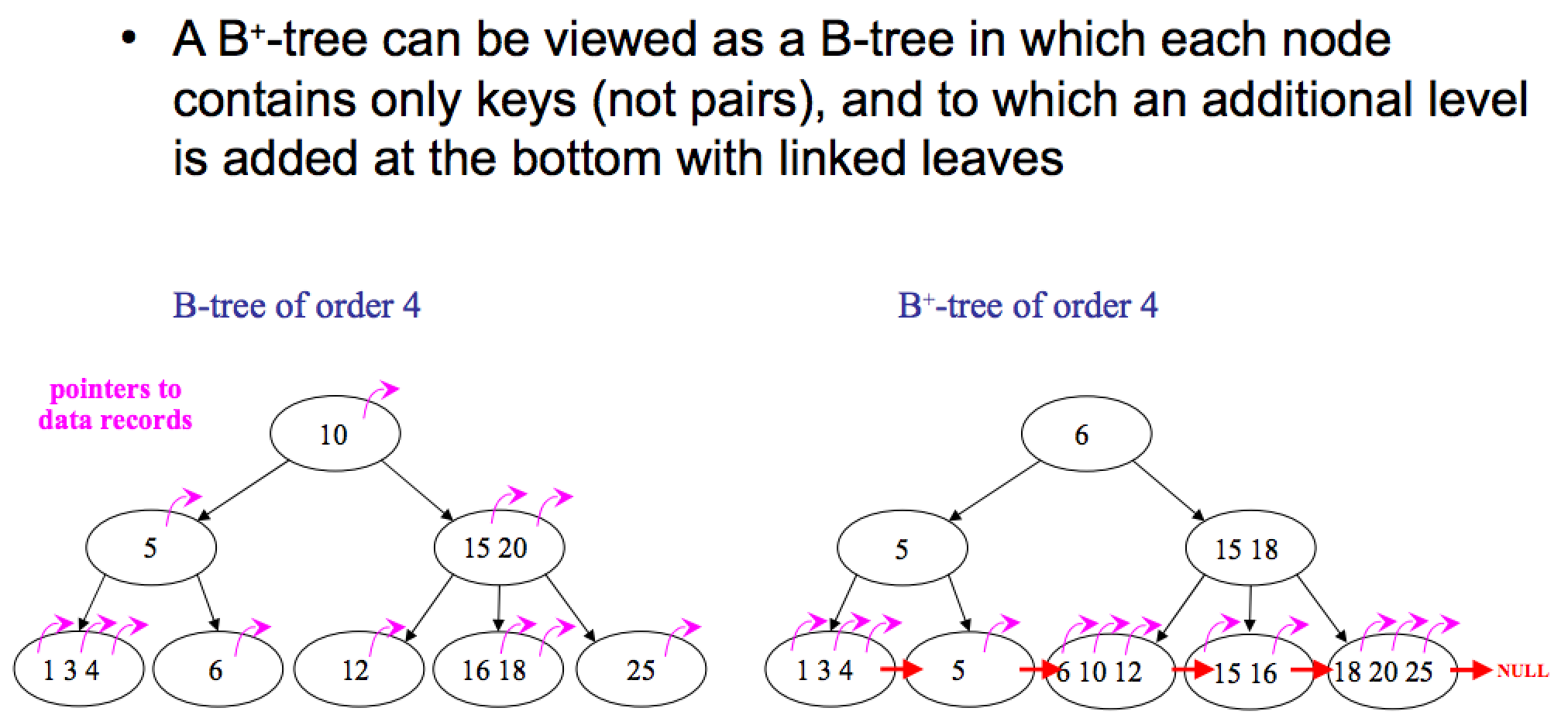
B* strom
B* strom – odrůda B strom, ve kterém je každý uzel stromu alespoň z ⅔ plný (na rozdíl od B-stromu, kde je toto číslo 1/2). B+ strom, který tyto požadavky splňuje, se nazývá B+* strom.
B* strom je relativně kompaktnější, protože každý uzel je plně využit. Jinak se tento typ stromu neliší od jednoduchého. B strom.
Abychom splnili požadavek, aby byl uzel alespoň ze 2/3 plný, musíme upustit od jednoduchého postupu rozdělení přetékajícího uzlu. Místo toho dochází k „transfuzi“ do sousedního uzlu. Pokud je zaplněn i sousední uzel, pak se klíče rozdělí přibližně stejně do 3 nových uzlů.
Strom LSM
LSM– strom (Log-strukturovaný slučovací strom – log-strukturovaný strom se slučováním) je datová struktura používaná v mnoha DBMS, která poskytuje rychlý přístup podle indexu v podmínkách častých požadavků na vkládání (například při ukládání transakčních logů). Stromy LSM, stejně jako jiné stromy, ukládají páry klíč–hodnota. Strom LSM podporuje dvě nebo více různých struktur, z nichž každá je optimalizována pro zařízení, ve kterém bude uložena. Synchronizace mezi těmito strukturami probíhá v blocích.
Princip činnosti
Jednoduchá verze stromu LSM, dvouúrovňový strom, se skládá ze dvou stromových struktur C0 a C1. C0 má menší velikost a je celý uložen v paměti RAM, zatímco C1 je v energeticky nezávislé paměti. Nové záznamy jsou vloženy do C0. Pokud po vložení velikost C0 překročí určitou specifikovanou prahovou hodnotu, souvislý segment je odstraněn z C0 a sloučen s C1 na trvalém úložném zařízení. Dobrého výkonu je dosaženo díky skutečnosti, že stromy jsou optimalizovány pro jejich ukládání a slučování se provádí efektivně a ve skupinách několika záznamů pomocí algoritmu připomínajícího slučovací řazení.
Většina LSM stromů používaných v praxi implementuje několik úrovní. Úroveň 0 (říkejme jí MemTable) je uložena v paměti RAM a může být reprezentována běžným stromem. Data na perzistentních úložných zařízeních jsou ukládána ve formě tabulek seřazených podle klíče (SSTable). Tabulku lze uložit jako jeden soubor nebo jako sadu souborů s nesouvislými hodnotami klíčů. Chcete-li najít konkrétní klíč, musíte zkontrolovat jeho přítomnost v MemTable a poté projít všechny SSTables na trvalém úložném zařízení.
Schéma práce se stromem LSM:
- Indexy SSTable jsou vždy načteny do paměti RAM;
- záznam je proveden v MemTable;
- při čtení se nejprve zkontroluje MemTable a poté, pokud je to nutné, SSTable na perzistentním paměťovém zařízení;
- periodicky se MemTable vyprázdní do energeticky nezávislé paměti pro trvalé uložení jako SSTable;
- SSTables na perzistentních úložných zařízeních se pravidelně slučují.
Klíč, který hledáte, se může objevit v několika tabulkách na perzistentních úložných zařízeních najednou a konečná odpověď závisí na programu. Většina aplikací potřebuje pouze poslední hodnotu spojenou s daným klíčem. Jiní, jako je Apache Cassandra, ve kterých je každá hodnota řádek v databázi (a řádek může mít různý počet sloupců v různých tabulkách z perzistentních úložných zařízení), musí nějak zpracovat všechny dostupné hodnoty, aby získali správný výsledek. Aby zkrátili dobu provádění dotazu, v praxi se snaží vyhnout situaci s příliš mnoha tabulkami na perzistentních úložných zařízeních.
Pro podporu B+-struktur, jako je bLSM[2] a Diff-Index, byla vyvinuta rozšíření metody „level“[3].
hodiny
Architektura stromu LSM umožňuje uspokojit požadavek na čtení buď z paměti RAM, nebo jedním přístupem k perzistentním úložným zařízením. Zápis je také vždy rychlý, bez ohledu na velikost úložiště.
SSTable na perzistentních úložných zařízeních je neměnný. Proto jsou změny uloženy v MemTable a odstranění musí přidat zvláštní hodnotu do MemTable. Protože k novým čtením dochází postupně v indexu, bude aktualizovaná hodnota nebo odstraněná hodnota nalezena před starými hodnotami. Pravidelné slučování starých SSTables na trvalém úložném zařízení provede tyto změny a skutečně odstraní a aktualizuje hodnoty, čímž se zbaví nepotřebných dat.
R-strom
R-strom (R-trees) – stromová datová struktura (strom). Je podobný B-stromu, ale používá se pro přístup k prostorovým datům, to znamená k indexování vícerozměrných informací, jako jsou geografická data s dvourozměrnými souřadnicemi (zeměpisná šířka a délka). Typický dotaz pomocí R-stromů může znít: „Najít všechna muzea v okruhu 2 kilometrů od mé aktuální polohy.“
Tato datová struktura rozděluje vícerozměrný prostor na mnoho hierarchicky vnořených a případně se protínajících obdélníků (pro dvourozměrný prostor). V případě trojrozměrného nebo vícerozměrného prostoru se bude jednat o pravoúhlé rovnoběžnostěny (kvádry) nebo rovnoběžníky.
Algoritmy vkládání a mazání používají tyto ohraničovací rámečky, aby zajistily, že objekty „v blízkosti“ budou umístěny do stejného vrcholu listu. Zejména nový objekt spadne do vrcholu listu, který vyžaduje nejmenší rozšíření jeho ohraničujícího obdélníku. Každý prvek vertexu listu ukládá dvě datová pole: způsob, jak identifikovat data popisující objekt (nebo data samotná) a ohraničující obdélník tohoto objektu.
Podobně vyhledávací algoritmy (např. průnik, zahrnutí, sousedství) používají ohraničující rámečky k rozhodnutí, zda hledat podřízený vrchol. Většina vrcholů se tedy během vyhledávání nikdy nedotkne. Stejně jako u B-stromů je tato vlastnost R-stromů činí užitečnými pro databáze, kde lze vrcholy podle potřeby vyměnit na disk.
K rozdělení přeplněných vrcholů lze použít různé algoritmy, což vede k rozdělení R-stromů na podtypy: kvadratické a lineární.
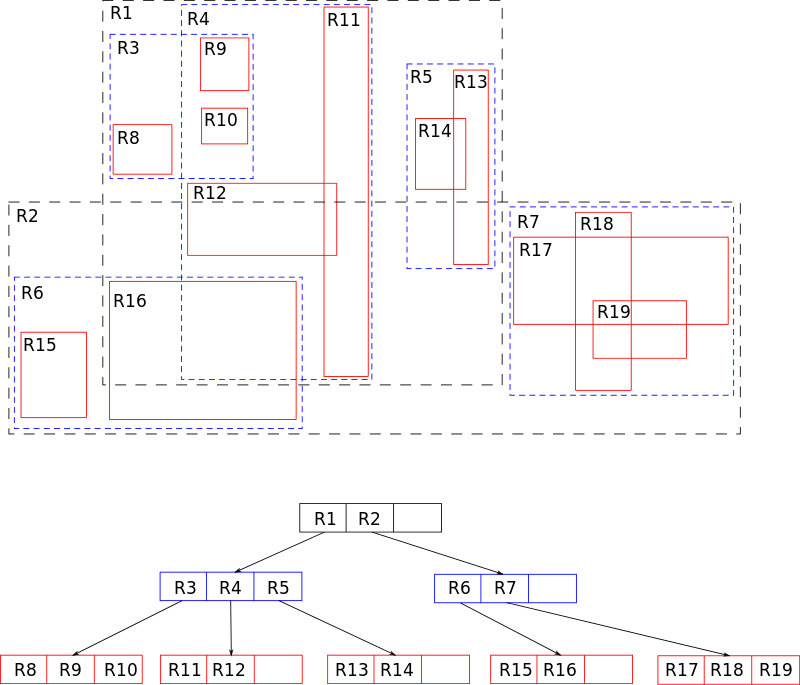
R-stromová struktura
Každý vrchol R-stromu má proměnný počet prvků (ne více než určité předem stanovené maximum). Každý prvek nelistového vrcholu ukládá dvě datová pole: jak je podřízený vrchol identifikován, a ohraničující obdélník (kvádr) obklopující všechny prvky tohoto podřízeného vrcholu. Všechny uložené n-tice jsou uloženy ve stejné hloubkové úrovni, takže strom je dokonale vyvážený. Při navrhování R-stromu musíte nastavit některé konstanty:
- MaxEntries — maximální počet potomků ve vrcholu
- MinEntries — minimální počet potomků ve vrcholu, s výjimkou kořene.







